Training Transformers at Scale With PyTorch Lightning
Introducing Lightning Transformers, a new library that seamlessly integrates PyTorch Lightning, HuggingFace Transformers and Hydra, to scale up deep learning research across multiple modalities.

Transformers are increasingly popular for SOTA deep learning, gaining traction in NLP with BeRT based architectures more recently transcending into the world of Computer Vision and Audio Processing.
However, training and fine-tuning transformers at scale is not trivial and can vary from domain to domain requiring additional research effort, and significant engineering.
Lightning Transformers gives researchers a way to train HuggingFace Transformer models with all the features of PyTorch Lightning, while leveraging Hydra to provide composability of blocks and configs to focus on research.
If you want to combine the expansive collection of HuggingFace models and datasets with the comprehensive features of Lightning, including Model Pruning, Quantization Aware Training, Loggers, Callbacks, or Lightning’s distributed accelerator plugins such as Sharded Training or DeepSpeed which can be extended for your own research applications — this library is for you.
In this blog post, we’ll show you how to use Lightning Transformers to fine-tune any HuggingFace Transformers model or dataset, using advanced performance features of Lightning.
Getting Started — Lightning Transformer Tasks
Lightning Transformers is a collection of tasks, where each task is composed of four key components required for training, validation, and testing.
- Model — The task-specific “head” based on your downstream task
- Backbone — The pre-trained Transformer model, such as BERT
- Tokenizer (Optional) — Required for NLP when tokenizing text
- Dataset — The data source for training, testing, validation, and inference
Lightning Transformers defines pre-made tasks and components which can be modified, swapped, or removed. This allows for reusability and simplicity when training your own Transformer models and makes it extremely easy to swap components via the CLI or within code.
We built Lightning Transformers with Hydra at the core, a powerful configuration framework that allows you to break down complicated configurations into composable components and modify your configs on the fly using your command line. Hydra makes it really simple to modify models, backbones, datasets, trainer configurations, optimizers, schedulers, and more in Lightning Transformers without touching the code.
Lightning Transformers currently support most NLP tasks, including Text Classification, Token classification, Multiple Choice, Translation, Summarization, and Question Answering with further modalities and tasks coming in the future.
Additionally, Datasets, Data Processing and Tasks are extendable for research work.
Custom Datasets, Data Processing, and Tasks
You can extend the built in Tasks with your own data files for training, testing and prediction and extend pre-made datasets as outlined in the following docs.
Tasks interface can be extended to support new custom tasks that benefit from all of Lightning Transformer’s out of the box features.
Finetuning Transformers
When fine-tuning a transformer model for your downstream task, there are five main points you need to consider:
- What Task do I want to fine-tune my model on?
- What pre-trained backbone do I want to fine-tune?
- What dataset do I want to fine-tune on?
- How do I want to train the model (i.e hyper-parameters, precision, tokenizer)?
- What optimizations might be useful? In some cases, you would want to enable features such as Pruning or Quantization or apply the Lottery Ticket Hypothesis to find the best model, faster. In a research setting, you may also want to swap optimizers, try different scheduling and fine-tuning freeze strategies.
With Lightning Transformers this is extremely simple:
- Pick the task you’d like to train (i.e Translation)
- Pick the backbone Transformer (i.e T5)
- Pick the dataset (i.e WMT16)
- Use the Lightning Trainer
Example: Finetuning Transformers for Machine Translation

Let’s say you want to finetune a pre-trained model to perform translation using the WMT16 dataset, translating from English to Romanian whilst enabling GPU training and Lightning model pruning. All you need is this command:

python train.py task=nlp/translation dataset=nlp/translation/wmt16 trainer.gpus=1 +trainer/callbacks=model_pruning- Pick the translation task (task=nlp/translation)
- Pick the backbone Transformer (By default, this it T5 for translation)
- Pick the dataset (dataset=nlp/translation/wmt16)
- Use the lightning trainer to use GPUs and model pruning to X
So how does this work? The transformer task uses configs, relying on Hydra to instantiate the task, backbone, optimizer, and scheduler. Hydra configs allow you to swap components with a change of a CLI parameter whilst maintaining a clean and minimal code. You can swap the optimizer of your translation model without changing any code:
python train.py task=nlp/translation dataset=nlp/translation/wmt16 trainer.gpus=1 +trainer/callbacks=model_pruning optimizer=rmspropTo increase the number of GPUs, you can simply override the Lightning trainer parameters:
python train.py task=nlp/translation dataset=nlp/translation/wmt16 trainer.gpus=4 +trainer/callbacks=model_pruningYou have access to all Lightning’s Features from the Trainer via the CLI. Everything is built from config objects and composed at runtime by Hydra. This makes experimentation extremely fast.
We also support using just code without Hydra. Below is the same Translation Task applied to the WMT16 dataset whilst applying the Lottery Ticket Hypothesis.
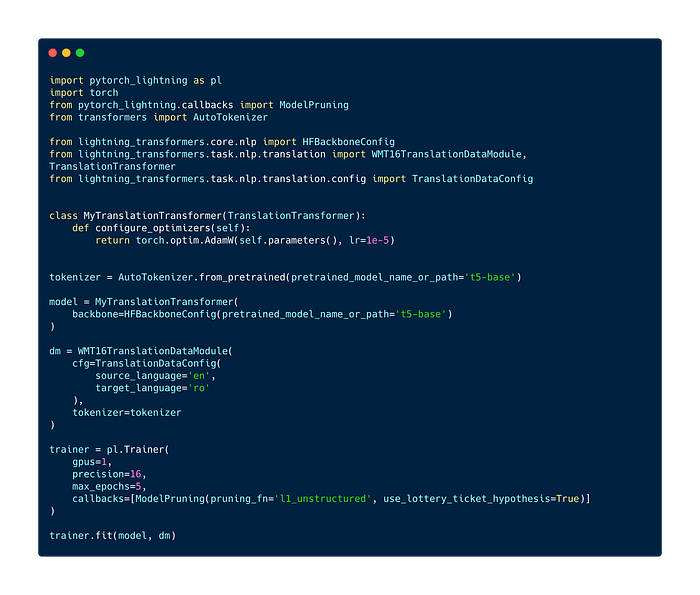
Lightning Transformers Distributed Training
Lightning offers a host of training optimizations to reach large parameter sizes and train efficiently on multiple GPUs. When fine-tuning billion parameter Transformer models, these distributed optimizations become essential to training. In some cases, optimizations require tuning and configuration, such as DeepSpeed which relies on various distributed communication parameters to be set, which can vary per model and per distributed environment.
Lightning Transformers provides out-of-the-box configurations for popular plugins such as Sharded Training or DeepSpeed, to make it extremely simple to enable for finetuning your own Transformer models. By appending a flag, you can enable the configs and train efficiently across multiple GPUs and leverage all the capabilities that DeepSpeed ZeRO and Sharded training have to offer.
To enable Sharded Training:
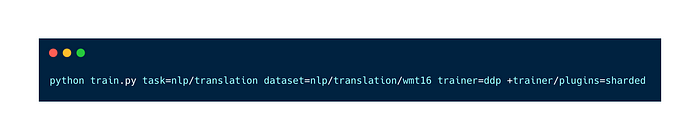
To enable DeepSpeed:

Next Steps
Give Lightning transformers a try! Try running the Translation demo with Grid.ai.
For more information check out the Transformers Repo and read our docs. We suggest you start with the quick start guide, but you can find all info such as X and X.
You can also run any model with you Grid.ai account. If you do not have a grid account yet. You can sign up for free with a GitHub or Google account with the link below.
You are more than welcome to join our slack community if you have any questions and discussions. We would love to hear from you what is useful? Feel free to ask questions in the comments.

