Lightning Flash 0.3 — New Tasks, Visualization Tools, Data Pipeline, and Flash Registry API

Lightning Flash is a library from the creators of PyTorch Lightning to enable quick baselining and experimentation with state-of-the-art models for popular Deep Learning tasks.
We are excited to announce the release of Flash v0.3 which has been primarily focused on the design of a modular API to make it easier for developers to contribute and expand tasks.
In addition to that, we have included 8 new tasks across the Computer Vision and NLP domains, visualization tools to help with debugging, and an API to facilitate the use of existing pre-trained state-of-the-art Deep Learning models.
New Out-of-the-Box Flash Tasks
Flash now includes 10 tasks across Vision and NLP! Any task can easily be used for finetuning or predicting.
Computer Vision
Multi-label Image Classification- The ability to categorize an image into multiple classes can be useful to create applications such as categorizing movies into genres using their posters, or detecting plant diseases.

The snippet below shows how to easily create a fine-tuning pipeline for image classification with multi-label support, using ImageClassifierwith pre-trained state-of-the-art backbone models.

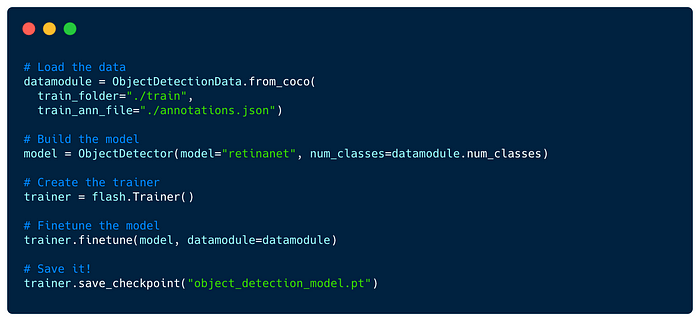
Object Detection The detection of objects in images is useful for applications like traffic control, license plate detection, or OCRs.

In this example, we finetune a custom ObjectDetector with the COCO dataset and a RetinaNet backbone model:
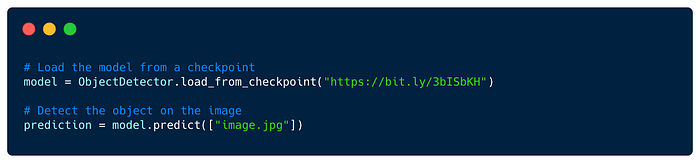
You can also use the Flash pre-trained ObjectDetector for predictions with just a few lines of code:
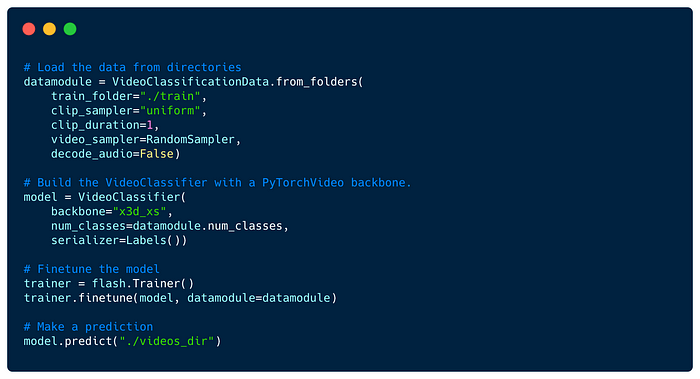
Video Classification- the task of producing a label for actions identified in a given video. Flash includes a VideoClassifier that leverages PyTorchVideo.
Code showing the VideoClassification with PyTorch Videos pretrained x3D model.
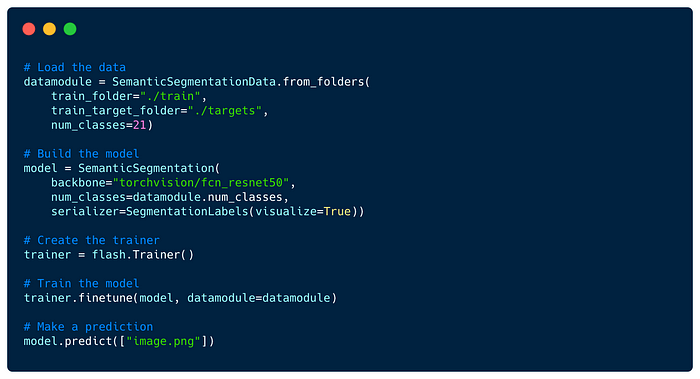
Semantic Segmentation- Classify at pixel level or image regions to given classes.

Code showing the SemanticSegmentation with torchvision pretrained FCN model.
Style Transfer — Transfer the style of an image from one domain to another.

We thanks Phillip Meier (@pmeier), the main author of PyStiche for contributing this StyleTransfer Task.
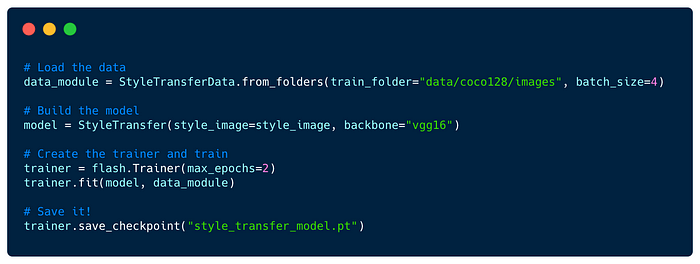
Image Embedder- Generate image vector encodings that can be used for tasks such as clustering, similarity search, or classification.
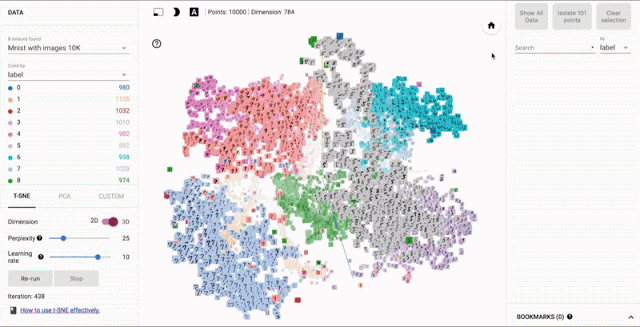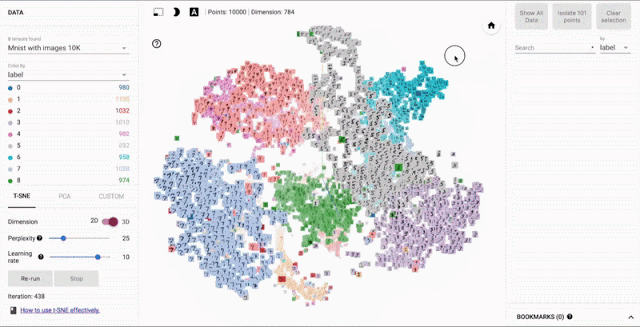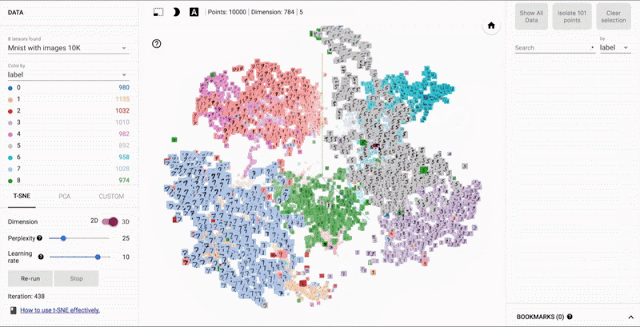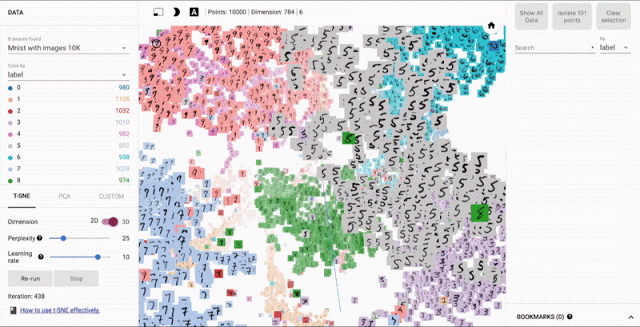
Code showing the usage of ImageEmbedder API to generate image embeddings.
NLP
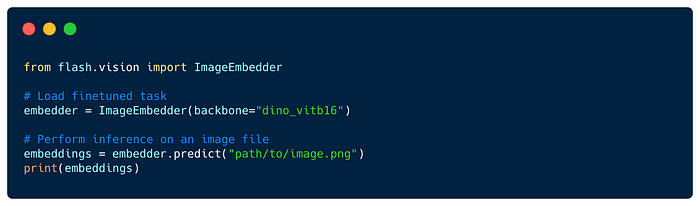
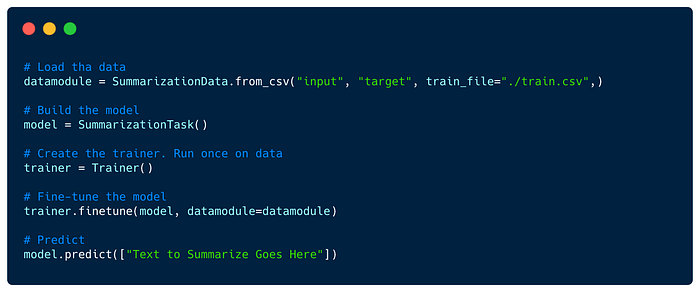
Summarization- Summarize text from a larger document/article into a short sentence/description.
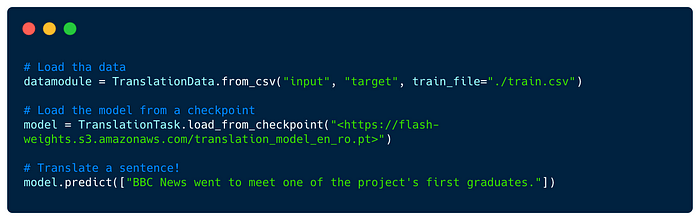
Translation- Translate text from a source language to another, such as English to Romanian.
New Features
Model Hub Intergrations
In this release, we integrated several model hubs such as Hugging Face, TIMM, PyTorch Video all accesible from Flash Tasks enabling you to train, finetune and inference thousands of SOTA models out of the box.
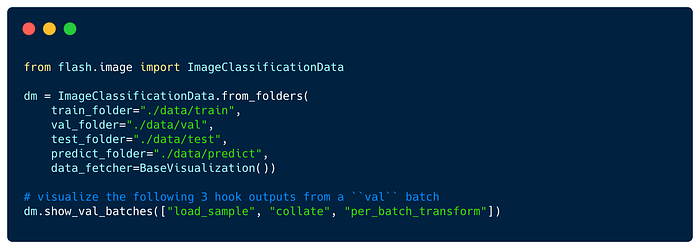
Task Visualization
We additionally added easy-to-use visualization callbacks to Flash tasks, which are useful to visually inspect the impact of different transforms on your data before launching a training.

You can implement custom visualization by subclassing a BaseVisualization callback- simply override any of the show_{preprocess_hook_name} to get the associated data and visualize it.
Contribute Your own Task
This release of Lightning Flash goes beyond finetuning, predicting, and visualizing out-of-the-box tasks. It includes APIs that give you the flexibility to extend and customize your Tasks, with little to no boilerplate.
You can now create a reusable and modular data processing pipeline, add visualization methods, and register model backbones for any task, making the Flash tasks a lot more structured!
Here are some example Scenarios that we would love for the community to help contribute to as either as new Tasks:
- Visual Question Answering
- Optical Character Recognition
- Graph Classification
- Speaker Recognition
- Audio Classification
- Face Detection
- Coreference Resolution
- Time Series Forecasting
For more details check out this detailed guide on how to contribute a task to flash.
New Task API Design and Improvements
In the next section, we will go over the new improvements for data and task flexibility.
Data Processing in Flash
To make data processing in flash more customizable and reusable, we created a few new components, creating a standard for the data pipeline.
Hooks
Lightning Flash API, just like PyTorch Lightning, is built as a collection of hooks- methods you can override to customize the behavior at different points of the model pipeline. This pipeline is comprised of 4 main routines: training, validation, testing, and predicting.
You can further customize any Flash hook for specific routines by adding a {train, val, test, predict} prefix to the hook's name.
For example, Flash DataSource has a load_data hook. Overriding it will modify the data loading behavior for all routines, but you can also override train_load_data to modify the data loading logic only in training.

Data Loading
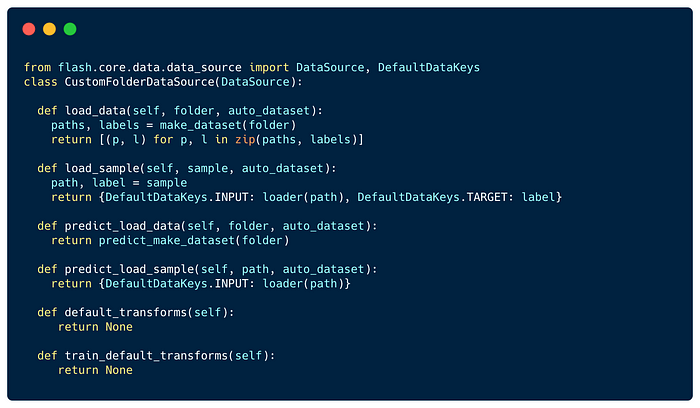
DataSource provides a hook-based API for creating data sets. It includes 2 hooks for data loading: load_data and load_sample.
load_data takes any input, such as directory, zip file, etc, and returns a sequence or iterator of samples, which will be used as input for load_sample, that returns the loaded sample. We found good practice for the load_sample to return a dictionary with an input and a target.
In this example:
load_datatakes a folder path and returns a list of input paths and their labels.load_sampletakes sample metadata as input, and returns a dictionary with a loaded object and its target.
Data Transforms
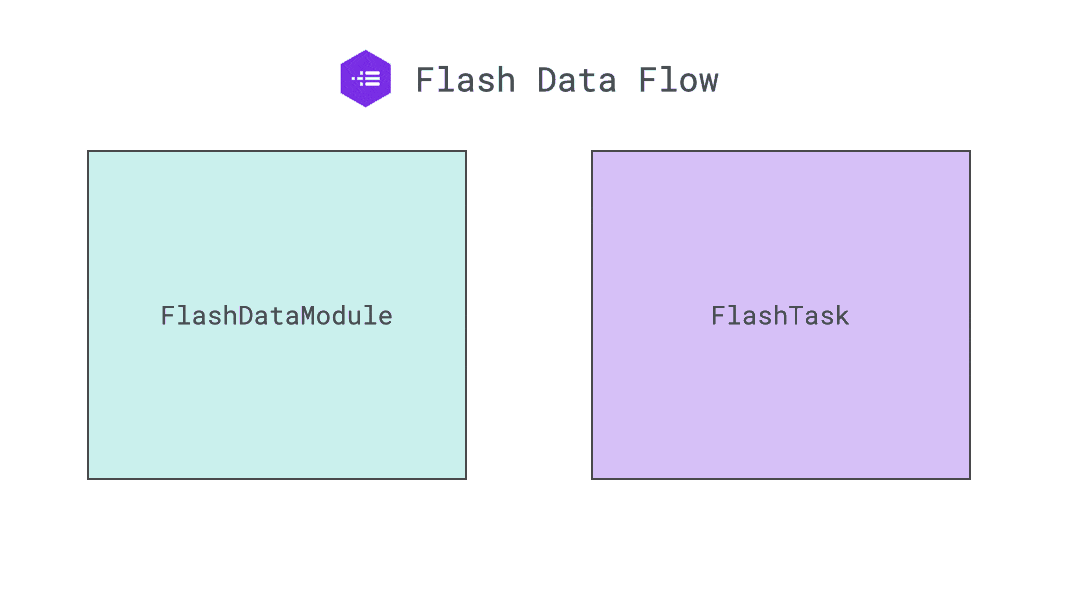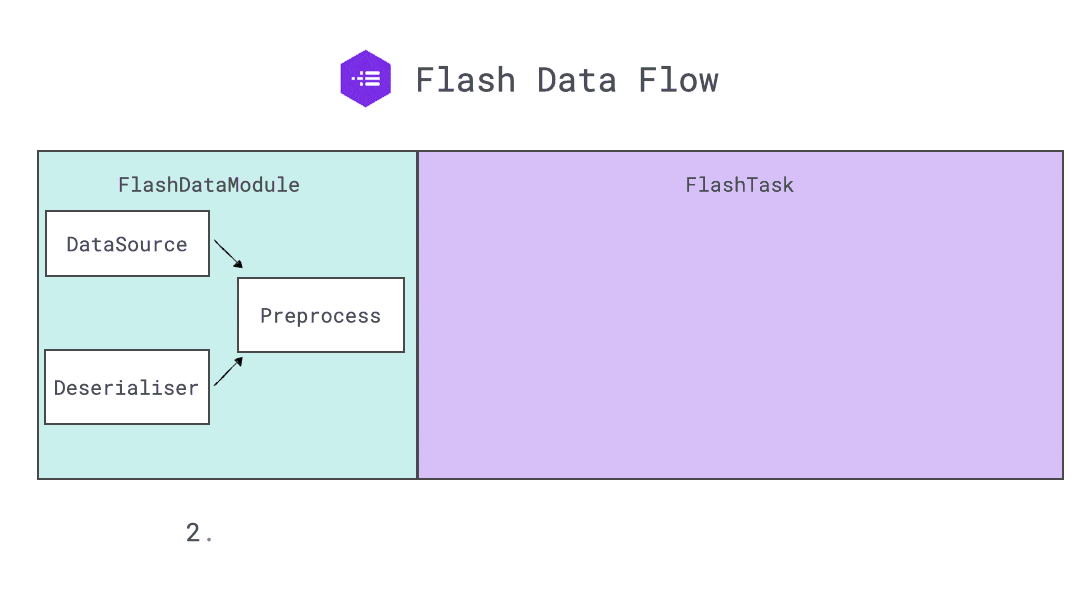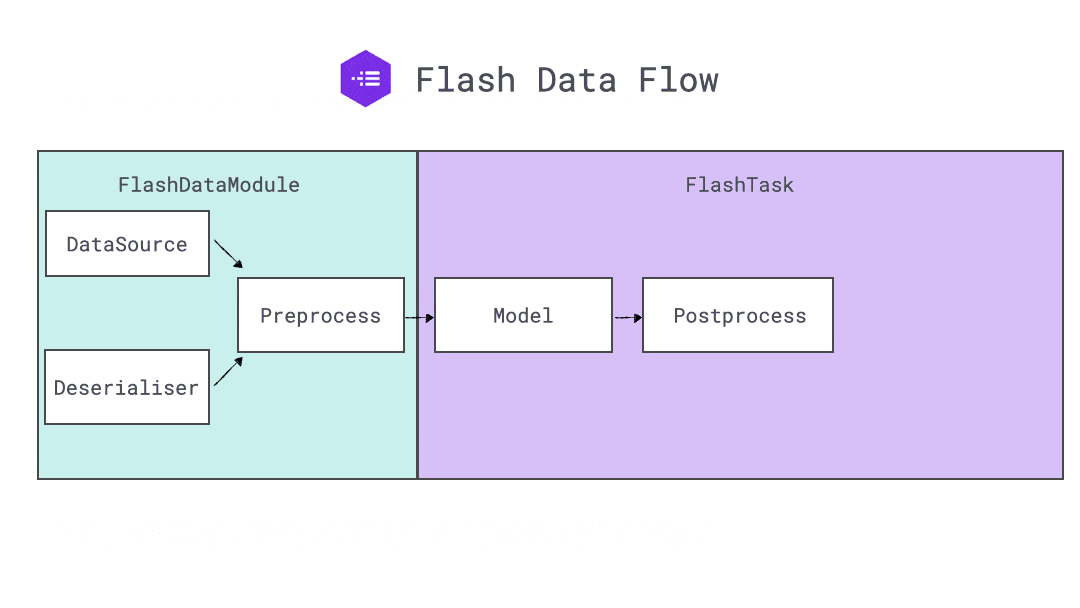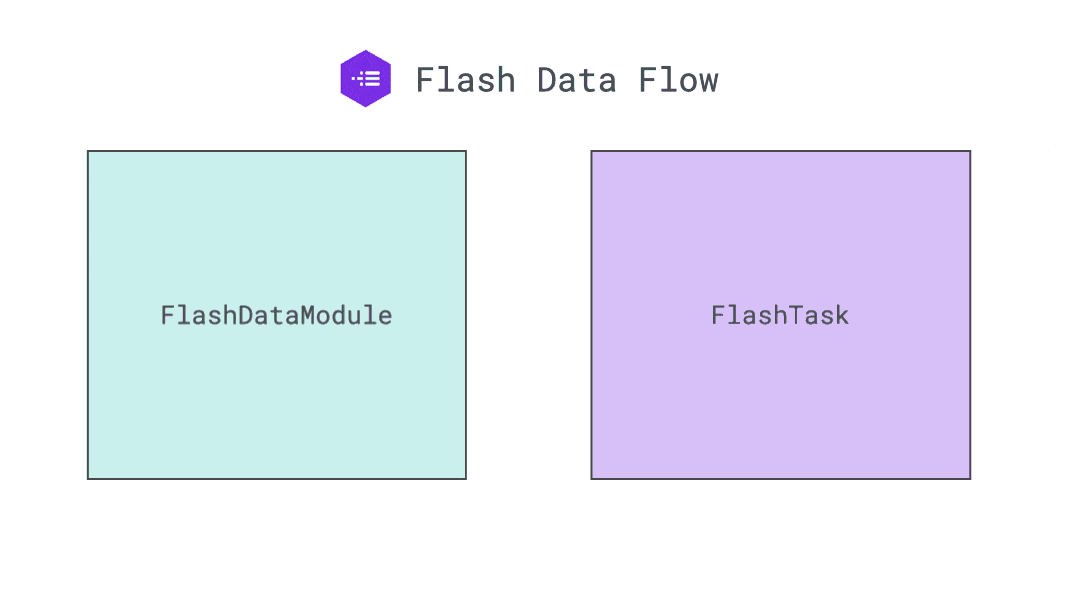
The Preprocess object provides a series of hooks encapsulating all the data processing logic that should run before the data is passed to the model. Decoupling the preprocessing logic reduces the engineering overhead used for inference on raw data or for deploying a model in a production environment, compared to a traditional PyTorch Dataset.
The Preprocess holds the DataSource instances and all the different routine transforms.
In Flash, the transforms are expected to be dictionary mapping a hook name to a given callable e.g. using batched transforms from Kornia.
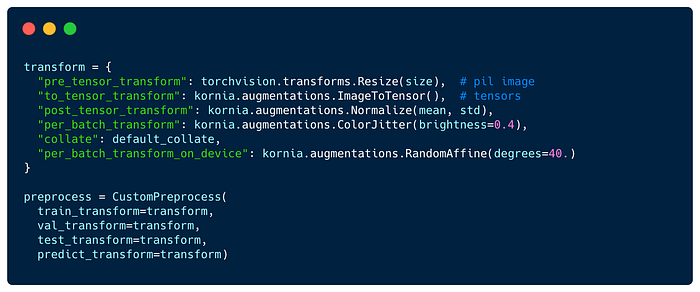
Flash implements an internal mechanism to apply your transforms at the right time.
The pre_tensor_transform, to_tensor_transform, post_tensor_transform, collate and per_batch_transform transforms will be injected directly as PyTorch DataLoader collate_fn function. This enables your transforms to be applied in parallel when setting num_workers > 0.
The per_sample_transform_on_device, collate and per_batch_transform_on_device transforms will be applied after the data have been transferred to GPU or TPU.
Finally, the default_transforms hook exposes the defaults transforms associated with a Task's Preprocess.
Predictions Transforms
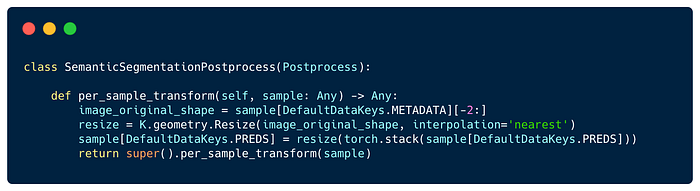
Similar to Preprocess, the Postprocess provides a simple hook-based API to encapsulate your post-processing logic. The Postprocess hooks cover everything from model outputs to predictions export.

For example, in the Semantic Segmentation Task, the shape of each image is added as metadata and the Postprocess will use each image metadata to resize its semantic prediction to its original size as follow:
Predictions Serializations
You can control the output format by overriding the Flash Serializer, which provides a method to convert model outputs (a tensor, after the Postprocess) to the desired prediction format.
For example, here’s a serializer that outputs probabilities (rather than logits):

You can change the serializer for your task by passing it to the model constructor, or by setting the models’ serializer property. Here’s an example where we use our probabilities serializer:
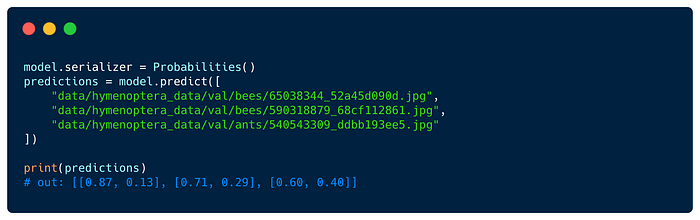
Read more on predictions in Flash here.
Flash Model Backbones
To make it easier to extend different model backbones in Flash tasks, we added the Flash Registry- an internal key-value database of models, making them accessible across the entire Flash codebase. Each Flash Task can include several registries as static attributes.
Here is how we registered all timm models within a TIMM_BACKBONES_REGISTRY.
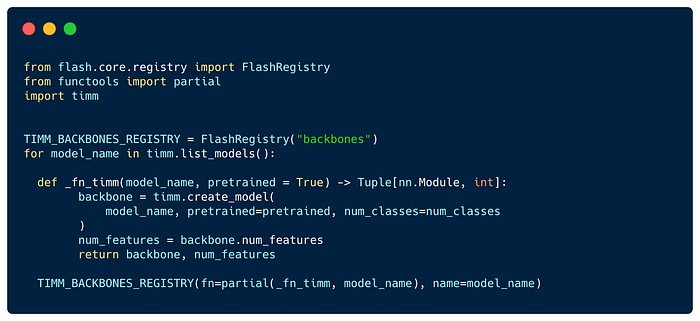
We are looking for community contributors to help integrate additional models and hubs with the new tasks release please reach out in GitHub or on Slack if you are interested in helping out.
Next Steps
To learn more about Flash, read the docs.
In the next releases we are planning to expand our task offering to new domains and use cases, feel free to open an issue or a PR with new tasks!
Join our slack to get involved!

